Our Blog
Explore the latest insights, product updates, and industry trends from our team.
Latest Articles
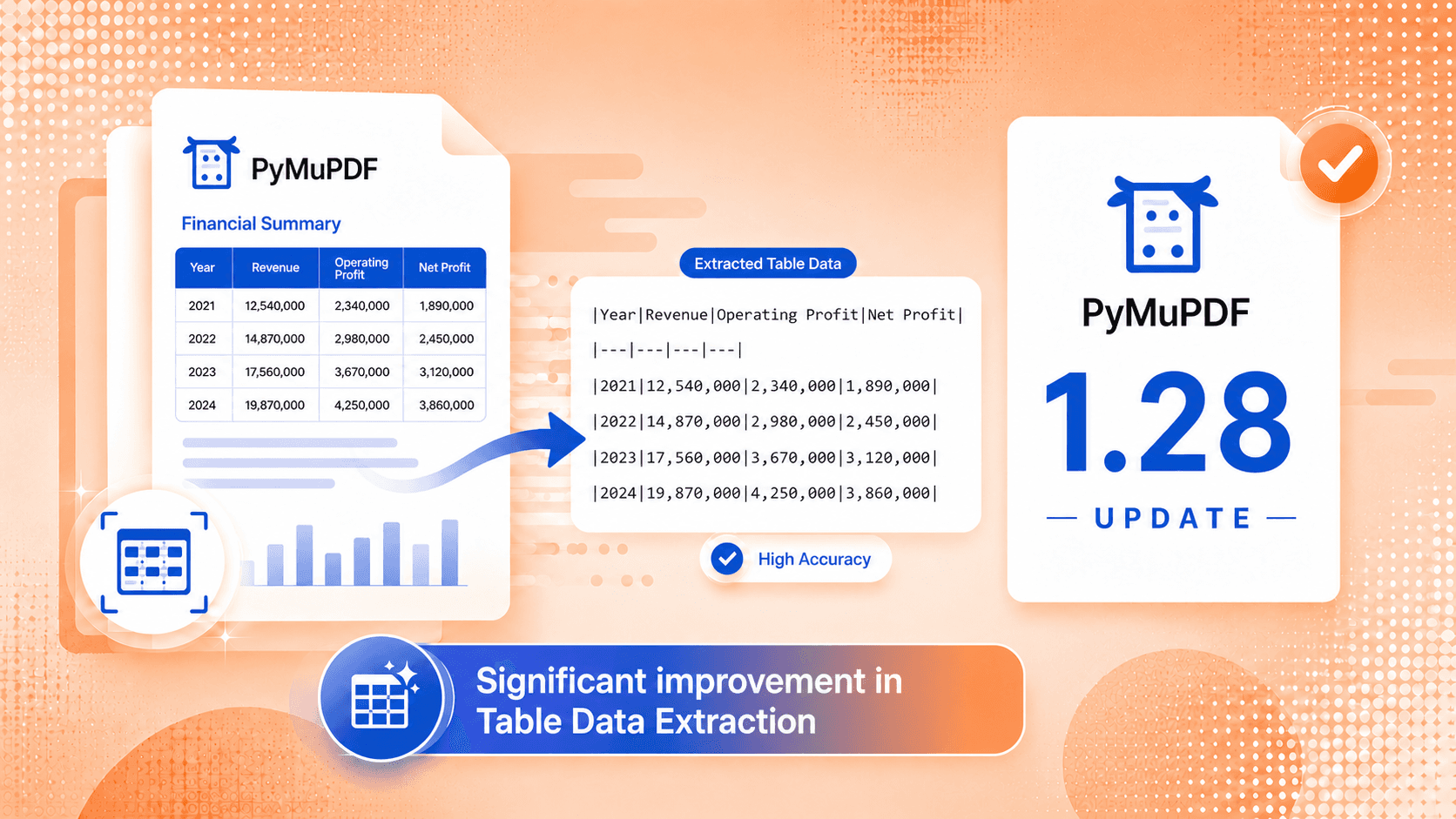




Case Studies
Tonic.ai specializes in data privacy and synthetic data generation within the software development sector. The company offers a suite of tools designed to de-identify and mimic data, enabling developers to work with realistic, production-like test data while ensuring privacy and compliance.
Kortext Ltd. is a global leader in digital learning and student engagement solutions. Their vision is to enable and enrich higher education by providing AI-powered content discovery, study platforms, learner analytics, and streamlined workflows for higher education staff.
Notion Labs, Inc. is a San Francisco-based software company that offers an all-in-one productivity platform designed to simplify workflows for individuals and teams. Their platform combines note-taking, task management, databases, and wikis into a unified workspace, allowing users to create notes, to-do lists, databases, and more.
Kolena Inc. is a company focused on AI quality assurance and data analysis within the artificial intelligence and machine learning sectors.








