Efficient Invoice Generation With PyMuPDF
Harald Lieder·November 26, 2023

PyMuPDF is a Python library that provides a wide range of features for working with document files. Among the emerging, most useful features of PyMuPDF is its ability to generate professional reports with a minimum of coding effort.
PyMuPDF report generation is based on its Story feature, which is explained in articles PyMuPDF’s New ‘Story’ Feature Provides Advanced PDF Layout Styling and How to Layout Articles Using PyMuPDF’s Story Feature.
For simplifying report generation, we have put all the technical details around PyMuPDF’s Story feature under the hood, so you as the developer can focus on the functional aspects of the reports.
In this article, we will create a typical invoice report, where the single items are stored in a database, a JSON file, or a CSV file.
We have tried to come up with an example that keeps a good balance between moderate technical challenges and meaningful functional complexity.
But let’s first better define the basics of what we are going to talk about.
Background
When we speak of reports, we usually refer to classifiable types of PDF output, based on data that are contained in databases. Typical examples include invoices, financial statements or text-oriented articles — possibly including images either in the form of company logos or mixed into the text.
Often enough, longer parts of text are being followed by tabular data with more text to follow.
Sometimes, text sections should be distributed over two columns of the page, whereas subsequent sections should be shown in only one column.
PyMuPDF covers these requirements while keeping coding effort to a minimum. As we will show you, the better part of all your report creation effort will be defining and refining the HTML sources of which your report will be composed.
PyMuPDF’s approach to create a report includes the following steps:
- Analyze the desired layout of the report pages. There may be a company logo and a common header to show on all pages. Or some introductory content, only to be shown on page one or, similarly, some closing text with legal information on the last page.
- Variable data, like single invoice items, are normally extracted from some database and reported in tabular format across multiple pages (and to be positioned between desired page headers and footers).
- Create HTML sources that represent the report building blocks identified previously. These HTML sources may have a constant, invariable content, or may contain insertion points (“variables”) for data fetched from some data sources.
- Tables typically are more complex building blocks. The developer will need to develop code that accesses a database (SQL, JSON, CSV, etc.) to fill each table cell of a row. Potentially also calculations are needed to tally invoice totals or to compute inter-field data like percentages. In the end, a list of table rows will be given to the report generation engine which in turn places these data on the report.
- For each HTML source, create a report section. These objects are the building blocks used by the report generator (represented by a Report object) to fill the pages. PyMuPDF currently has three types of these building blocks: Block, ImageBlock and Table. Details about these objects all fit together are explained below.
- For producing an invoice, in this article we have identified HTML sources to define a header, a “prologue” (an introduction only shown on page one) and a table to contain the invoice data. We do not need a special footer block: just showing page numbers is good enough. We also want to give each page a company logo in the top-left corner.
So our invoice report will have the following structure:
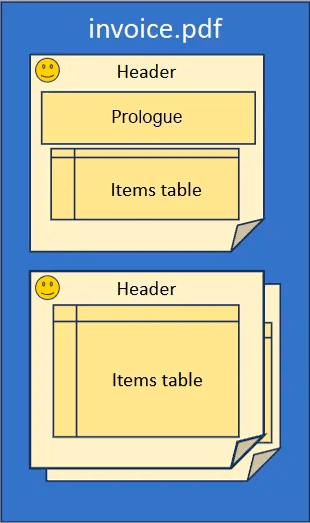
Creating an Invoice
Our invoice will show a different layout on page one than on the other pages. All pages however share the logo, the header and the invoice table.
We will need to define three HTML sources: “header.html”, “prologue.html” and “items.html”. For the header and the prologue, the building block “Block” is sufficient.
For the logo, we will additionally use an ImageBlock.
The invoice items are located in a database and need to be shown by some tabular layout on the pages. Because we cannot know the size of the resulting table beforehand, the obvious choice is Table. This class supports automatic top-row repeat, choice of alternating row background colors and a callback function for providing the table data.
The fields of the items table row are represented by identifiers (HTML “id” tags within “items.html”). The Table needs to know these identifiers in order to fill in values. All this will become clearer a little later.
Let us have a look at the code that represents our preparations so far:
import pathlib # for easy reading of text file content
import json # for reading external data
import pymupdf
# import required components from PyMuPDF Report collections
from pymupdf.reports import Report, Table, Block, ImageBlock
mediabox = pymupdf.paper_rect("letter-l") # page format: Letter landscape
# Create the overall report object
report = Report(mediabox)
# Predefined HTML to define the header for all pages
hdr_html = pathlib.Path("header.html").read_bytes().decode()
header = Block(html=hdr_html, report=report)
# Define the logo
logo = ImageBlock(url="logo.png", height=100, report=report)
# The prologue HTML basically is a skeleton with 4 variables
prologue_html = pathlib.Path("prologue.html").read_bytes().decode()
# After reading the HTML source, we access the content and fill in
# data for the variables.
supplier = json.loads(pathlib.Path("supplier.json").read_text())
prologue_story = pymupdf.Story(prologue_html) # prepare the story
body = prolog_story.body # access the HTML structure inside to fill in data
body.find(None, "id", "supplier").add_text(supplier["supplier"])
body.find(None, "id", "contact").add_text(supplier["contact"])
body.find(None, "id", "billto").add_text(supplier["billto"])
body.find(None, "id", "shipto").add_text(supplier["shipto"])
# To create the building block, we this time use the prepared Story:
prologue = Block(story=prologue_story, report=report)When defining the “prologue” block, we did not pass in the HTML source directly.
Instead, we created a Story to enable us replacing the variables “supplier”, “contact”, “billto” and “shipto” with corresponding data. Please take a look at the four statements above, which find the variables and replace them with values read from a JSON file.
To define our Table, more considerations are required. Let us start by looking at the HTML definition in “items.html” — which is quite simple:
/* an "id" is required to identify "top-row repeat"*/
/* required for cloning the row per item */
<table>
<tbody><tr id="toprow"><th>Line</th>
<th>H&P ID</th>
<th>Description</th>
<th>Part No.</th>
<th>Qty</th>
<th>UOM</th>
<th>Date</th>
<th>Unit Price</th>
<th>Total Price</th>
</tr><tr id="template"><td id="line"></td>
<td id="hp-id"></td>
<td id="desc"></td>
<td id="part"></td>
<td id="qty"></td>
<td id="uom"></td>
<td id="date"></td>
<td id="uprice"></td>
<td id="tprice"></td>
</tr>
</tbody></table>In essence we define the top row of the table and make it identifiable by some “id” (“toprow” — can be chosen as required). This row will be repeated on every page where parts of the table appear.
The second row is a template for showing the actual item details. This row must be named “template”. The “id” values for the single row fields must be known by the above mentioned callback function.
Code inside Table will clone the template row as many times as there are items in the database. Here is the building block definition:
# Read the HTML source code for the items table
items_html = pathlib.Path("items.html").read_bytes().decode()
items = Table( # generate a table object that can cross page boundaries
html=items_html, # HTML source
top_row="header", # identifies the table's top row
fetch_rows=fetch_rows, # callback to fetch invoice items
report=report, # pointer to owning report object
)By specifying parameter top_row (named “toprow” in the HTML), we automatically request that every output segment of the table should receive this header line. If the parameter is None (the default), top row repetition will not happen.
The most important parameter is fetch_rows. This must be a callable which returns all rows of invoice items. Where these data come from is completely up to this function. It could be an SQL database, a CSV or JSON file, a pandas DataFrame or anything else. However, the first of the returned rows must contain the list of id’s specified in the “template” row of the HTML source. So, in our example that row must be
[“line”, “hp-id”, “desc”, “part”, “qty”, “uom”, “date”, “uprice”, “tprice”].
At this point, we are done with our preparations.
We will now complete the definition of the report itself — by telling it, which building block must be used on which page(s). This is done by two simple statements:
# -----------------------------------------------------------------------------
# We have defined all required building blocks for the report.
# Now we define how they should be put on pages.
# -----------------------------------------------------------------------------
report.header = [logo, header] # will appear at the top of all pages
report.sections = [prologue, items]
# Done!To actually generate the PDF, only one more statement is required:
# This generates the report and saves it to the given path name.
report.run("invoice.pdf")Here is an example invoice produced by the above. Building blocks and their names are indicated in red.

And here follows a glimpse at page 2. Please note that the prologue is no longer included and the items are directly positioned underneath the header, as desired.

Conclusion
PyMuPDF’s new reporting feature provides efficient ways to quickly compose reports based on predefined HTML building blocks — thus making creative use of PyMuPDF’s Story class.
We are in the process of producing report examples beyond invoices. While the reporting is not yet fully integrated in PyMuPDF, you can already use it today. Please do have a look at this folder to see examples popping up.
Have a look at many more interesting articles on our Blog. Other PyMuPDF resources are our excellent documentation, the #pymupdf channel on Discord, and the interactive, installation-free playground pymupdf.io.
Discuss This Article with the Community
Have a question, a different approach, or something you built after reading this? Share it on the forum or join the Discord, we'd love to hear from you.