Why Data Chunking is Essential for LLM Processing
Jamie Lemon·December 12, 2025

The Context Window Challenge
Every LLM has a finite context window, which is the maximum amount of text it can process at once. While modern models boast impressive context lengths (sometimes exceeding 100,000 tokens), throwing entire documents or databases at an LLM rarely produces optimal results. The model needs to identify relevant information within that context, and as context grows, its ability to focus on what matters can diminish.
This is where chunking becomes invaluable. By breaking content into logical segments, you ensure the model receives precisely the information it needs without unnecessary noise.
Improved Retrieval Accuracy
In retrieval-augmented generation (RAG) systems, chunking directly impacts how well your application finds relevant information. When you embed and index smaller, focused chunks rather than entire documents, your vector database can return more precise matches to user queries. For example, a chunk about "quarterly revenue growth" is far more targetable than an entire annual report.
Think of it like organizing a library. Would you rather search through individual chapters or entire encyclopedias every time you need specific information?
Semantic Coherence
Good chunking strategies respect the natural structure of content. By breaking text at logical boundaries like paragraphs, sections, or topic shifts you preserve semantic meaning within each chunk. This helps the LLM understand context better and generate more accurate, relevant responses.
A chunk that discusses a complete concept is far more useful than one that cuts off mid-thought or mixes unrelated topics.
Cost and Performance Optimization
Chunking allows you to be selective about what you send to the LLM, reducing both API costs and latency. Instead of processing a 50-page document for a simple question, you can retrieve and process just the two or three relevant chunks.
This efficiency compounds across thousands of queries, making the difference between a practical application and an expensive experiment.
Strategies for Effective Chunking
The best chunking approach depends on your content and use case. Fixed-size chunks offer simplicity and predictability. Semantic chunking, which breaks content based on topic shifts or meaning, can provide better results but requires more sophisticated processing. Hybrid approaches that respect both size constraints and natural boundaries often strike the best balance.
The key is testing different strategies with your specific data and monitoring how well they serve your users' needs. Data chunking isn't glamorous work, but it's the foundation that makes LLM applications actually work in production.
Using Chunking with PyMuPDF Layout
PyMuPDF Layout ( when invoked by version 0.2.7, or above, of PyMuPDF4LLM ) now also supports page-based chunking.
For example, with a test file called pymupdf-layout-chunk.py :
import sys
import pymupdf.layout
import pymupdf4llm
import json
from pathlib import Path
filename = sys.argv[1]
chunks = pymupdf4llm.to_markdown(
filename,
page_chunks=True,
show_progress=True,
)
js = json.dumps(chunks)
Path(filename).with_suffix(".chunks.json").write_text(js)
Usage:
python pymupdf-layout-chunk.py input.pdf
Each item in the list "chunks" represents one page and is a dictionary containing the page text in MD format, accompanied by the document metadata, identified page boxes and if desired, a non-markdown, plain text version can also be reproduced by replacing pymupdf4llm.to_markdown() with pymupdf4llm.to_text().
Semantic knowledge
When PyMuPDF Layout is used in this way with page chunking an additional key on the output data is available with page_boxes - this key contains a list of identified sections on the page - semantically identified.
For example, page headers, section headers, captions, body text and tables can all be identified:
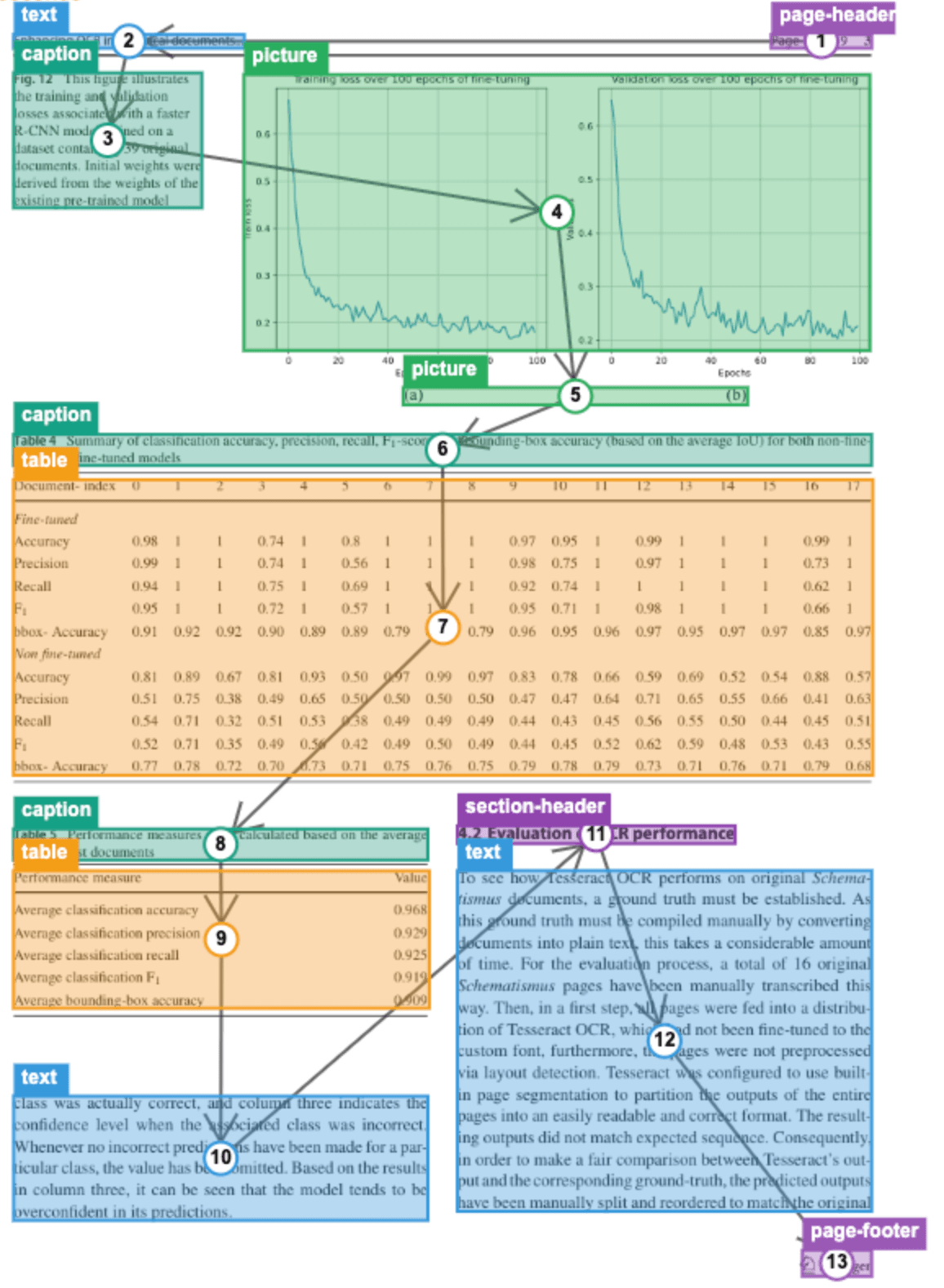
The resulting page based chunks can be then used to better discern the range of data you send to your LLM. For example, if you know your document has relevant financial information on a specific page, and that this is the only data which is important for your LLM, then that is the chunk of data which can be used.
In this case perhaps you just want all the table data sent to an LLM, then just grab that and that only.
Don’t send the whole document, just send the chunk!
Conclusion
Data chunking may seem like a technical detail, but it's actually one of the most impactful decisions you'll make when building LLM applications. By breaking content into thoughtfully sized pieces, you enhance retrieval accuracy, preserve semantic meaning, reduce costs, and ultimately deliver better results to your users. Start with a simple approach, measure its effectiveness, and refine as you learn what works best for your specific use case.
Remember, to reduce costs and increase efficiency, you don’t send the whole document, just send the chunks!
- Try the PyMuPDF Layout demo to discover more.
- Read the documentation for PyMuPDF Layout
Discuss This Article with the Community
Have a question, a different approach, or something you built after reading this? Share it on the forum or join the Discord, we'd love to hear from you.