Table Recognition and Extraction With PyMuPDF
Harald Lieder·August 23, 2023

Note
With PyMuPDF version 1.23.0, we have added the ability to extract tables from PDF documents. This is the first major version with more improvements in the pipeline over the next releases, which may require minor API changes.
Programmatically identifying tables on PDF pages and extracting their content is a capability in high demand.
Many companies all over the world have important, and even critical data, now only residing in tables inside PDF reports, that were created years ago.
While even simple, straightforward text extraction from PDFs can already be a challenge (see this article for some background), this is much more the case for tables.
The primary reason for this is that, from a PDF page’s perspective, a table is just text — amongst lots of other text. The PDF page does not “know” that it is showing a rectangular structure of rows and columns.
Therefore, table extraction involves identifying the border and the cell structure for each document table, such that it can be extracted and exported to some structured file format like Excel, CSV or JSON, or be otherwise handed on to downstream applications.
Enter PyMuPDF, a Python binding for the MuPDF library, which is known for its capabilities in rendering and extracting content from many document types.
Introduction to PyMuPDF
PyMuPDF is a Python binding for the MuPDF library, which is a lightweight PDF, XPS and e-book viewer. The PyMuPDF library not only supports reading and rendering PDF (and other) documents but also provides powerful utilities for manipulating PDFs.
With version 1.23.0, PyMuPDF has added table recognition and extraction facilities to its rich set of features. This article will guide you through the steps to finding and extracting tables.
Finding and Extracting Tables Using PyMuPDF
Let’s dive right into the process of locating and extracting tables on document pages, and exporting them to other formats like Excel.
1. Installation
Just to be sure we also cover this obvious prerequisite —
PyMuPDF’s installation is as straightforward as for any Python package. Execute the following command as usual in a terminal window of your computer:
pip install pymupdfPyMuPDF has no (mandatory) dependencies. It is self-sufficient and therefore ready to immediately take off at this point.
2. Opening a Document, Loading a Page and Searching for Tables
Now we can open a document, load one of its pages and look for tables present on it.
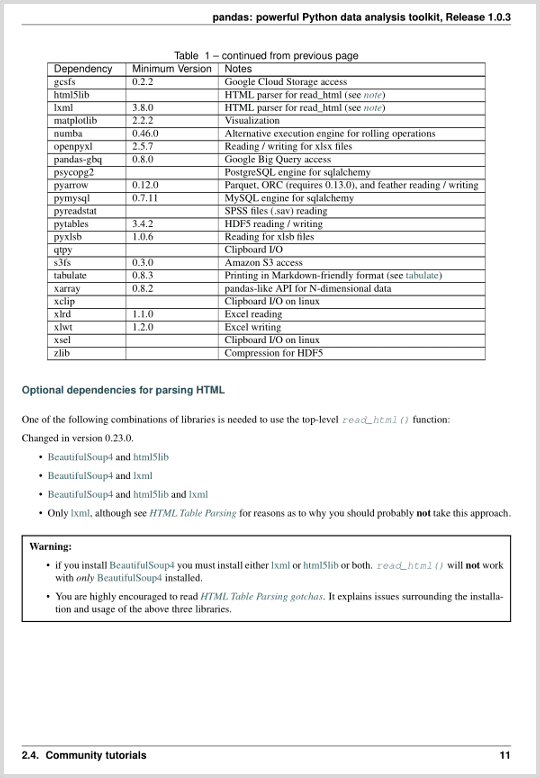
For reference, this is the PDF page we will work with (taken from the pandas manual):
import pymupdf
# Open some document, for example a PDF (could also be EPUB, XPS, etc.)
doc = pymupdf.open("input.pdf")
# Load a desired page. This works via 0-based numbers
page = doc[0] # this is the first page
# Look for tables on this page and display the table count
tabs = page.find_tables()
print(f"{len(tabs.tables)} table(s) on {page}")
# We will see a message like "1 table(s) on page 0 of input.pdf"3. Analyzing the Table
We know now that the page has exactly one table. Let us access it and research what we can see.
# object "tabs", among other things, is a sequence of the tables
tab = tabs[0]
type(tab)
<class 'pymupdf.table.table'="">
</class>Here is an overview of methods and properties of each table:
- The boundary box (
bbox) of the complete table is a tuple(x0, y0, x1, y1)of rectangle coordinates. - The single cells of the table are contained in the list
cells. Each one again is a rectangle tuple, obviously contained in the table’sbbox. As a point of caution: a cell may also beNoneif it does not exist at all. - The integers
col_countandrow_countare the number of columns, respectively rows. - Attribute
pageis a backreference to the owning page. - Method
extractextracts all text of the table as a list of lists, which each contain the string of the respective cell. We will see an example further down. - Method
to_pandasreturns a pandas DataFrame version of the table. To use this method, pandas must be installed, otherwise an exception is raised. - Attribute
rowsis a list of lists of cells in the respective row. - Finally,
headeris an object containing table header information. This object plays an important role when exporting to structured files and downstream program logic.bbox: the boundary box around header cellscells: the list of cells in the headernames: the list of column namesexternal: a bool indicating whether the header is outside the table boundary box (=True). IfFalse, the table’s first row contains header data.
The header object deserves some background information. On occasion, the algorithm locating the table will not identify column names. In these cases, additional logic investigates text “above” the table and tries to match it with the table’s column structure. Whatever the situation, the property external will help with finding out.
Here is a view on real data:
tab.bbox # bounding box of the full table
(96.78600311279297, 84.15399169921875, 515.2139892578125, 368.28900146484375)
tab.cells[0] # top-left cell
(96.78600311279297, 84.15399169921875, 171.68499755859375, 96.50799560546875)
tab.cells[-1] # bottom-right cell
(260.0830078125, 355.93499755859375, 515.2139892578125, 368.28900146484375)
tab.row_count, tab.col_count # row and column counts
(23, 3)
tab.page # backreference to the page
page 0 of input1.pdf
for line in tab.extract(): # print cell text for each row
print(line)
['Dependency', 'Minimum Version', 'Notes']
['gcsfs', '0.2.2', 'Google Cloud Storage access']
['html5lib', '', 'HTML parser for read_html (see note)']
…*** omitted data ***…
['xsel', '', 'Clipboard I/O on linux']
['zlib', '', 'Compression for HDF5']The following information is contained in the tab.header object:
header = tab.header # table header object
header.bbox # header bbox
Rect(96.78600311279297, 84.15399169921875, 515.2139892578125, 96.50799560546875)
header.cells[0] # leftmost header cell
(96.78600311279297, 84.15399169921875, 171.68499755859375, 96.50799560546875)
header.cells[-1] # rightmost header cell
(260.0830078125, 84.15399169921875, 515.2139892578125, 96.50799560546875)
header.external # header is part of the table itself!
False
header.names # these are the column names
['Dependency', 'Minimum Version', 'Notes']4. Exporting the Table
The PyMuPDF table access features deliver Python objects, most prominently among them are lists of strings for the cell content.
These are convenient starting points for exporting table data to downstream consumers. The most typical consumers are Excel and CSV files. In our example, we will convert the table to a DataFrame object of the well-known pandas package.
df = tab.to_pandas() # convert to pandas DataFrameUsing pandas features, the DataFrame can be printed or exported in a number of ways. Here we show how to save it as an Excel file (please consult the pandas manual for additional dependencies for doing this).
df.to_excel(f"{doc.name}-{page.number}.xlsx")And here is the generated Excel sheet:
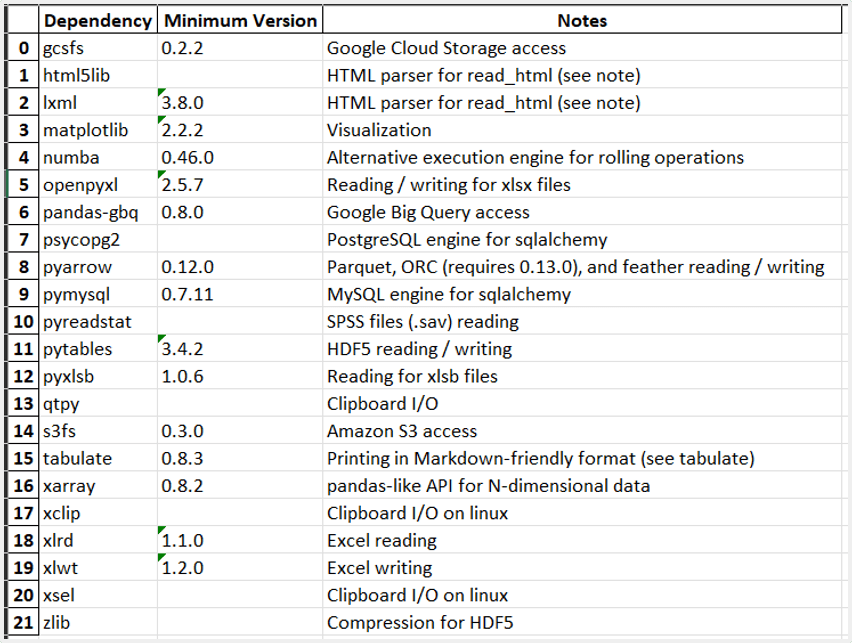
Conclusion
PyMuPDF offers a straightforward and efficient method for extracting tables from PDF (and other document type) pages.
Table data are extracted to elementary Python object types which easily lend themselves to be further processed by downstream software, for instance pandas.
Together with PyMuPDF’s superior text, image and vector graphics extraction features, the developer is in command of a complete toolset for document data extraction.
Learn how to navigate problems that may arise in table extraction with our next post: Solving Common Issues With Table Detection and Extraction.
To learn more about PyMuPDF, be sure to check out the official documentation: https://pymupdf.readthedocs.io/en/latest/.
If you have any questions about PyMuPDF, you can reach the devs on the #pymupdf Discord channel.
Discuss This Article with the Community
Have a question, a different approach, or something you built after reading this? Share it on the forum or join the Discord, we'd love to hear from you.