Solving Common Issues With Table Detection and Extraction
Harald Lieder·September 27, 2023

This article is a continuation of Table Recognition and Extraction With PyMuPDF, which gives an overview of the table extraction feature introduced in version 1.23.0.
We now want to dive one level deeper and show you how special situations are handled, or what you can do if table extraction does not work as expected.
For the sake of brevity, let’s assume you are familiar with the above article. Here is a list of situations we are going to cover:
- Your table is not a simple (n x m) rectangular scheme of n rows and m columns, but contains cells that are joined across multiple columns or rows.
- Your table cannot be recognized at all — for example because there are no gridlines wrapping the cells.
- Multiple tables are present, but not recognized as separate.
In the following sections we will cover these cases and suggest things you can do to deal with them.
Complex Tables
Tables are not always a simple rectangular scheme of n rows and m columns. There may be cells extending across neighboring columns or rows, or columns (rows) may not extend to the full table height or width. Look at the following example:
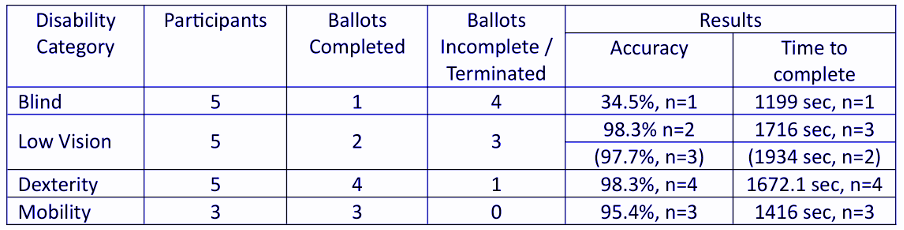
The last column “Results” is split in two sub-columns, and row “Low Vision” is split in two sub-rows within the last two columns.
Another observation: The content of some table cells consists of multiple lines.
How does table recognition handle this situation? Let’s look at the extracted cell text:
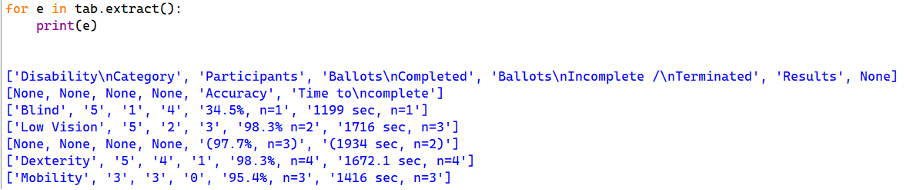
Observations
- Multi-line table cells are simply returned as is: the line breaks are part of the extracted text.
- Table cell splits are propagated to the full table:
- The sub-columns under column “Result” will establish an additional column.
- The header text (“Result”) above the split is assigned to the first sub-column. The second sub-column’s header reflects this by having no text and is set to
None. - In addition, an additional row has been generated (below the top row), which contains
Nonefor every original column outside the two sub-columns. - We see a similar action for row “Low Vision”: Two sub-rows have been created and instead of text,
Noneappears in every generated table cell.
The creation of sub-columns and sub-rows is also reflected in the list of table cell coordinates: every table cell with None instead of text has no boundary box.
The following image shows a red rectangle around every cell with a boundary box:
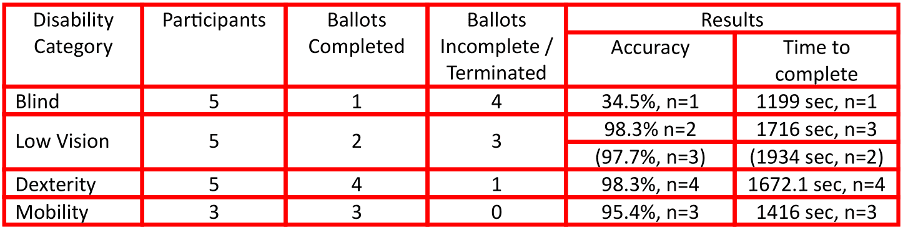
The row and column count properties of our table are 7 (rows) respectively 6 (columns).
Missing Gridlines
The most important guide for PyMuPDF’s table detector are graphical indicators like lines and rectangles. If a table has a grid indicating its structure (like in the above example), nothing can really go wrong.
If, however, vertical and/or horizontal graphics are missing, the situation may become ambiguous: tables may be not detected at all, columns may not be correctly separated from each other, multi-line cells may be treated as separate rows, etc.
In these situations, the many parameters of the find_tables() method often help achieve better results.
Modifying Detection Strategies
The table finder’s default detection strategy is called “lines”, which means it looks for vector graphics that serve as column and row separators: vertical_strategy="line", and horizontal_strategy="line".
If there is no horizontal (i.e. row-separating) information available, one can use horizontal_strategy="text" in which case text coordinates are used to internally generate row coordinates.
Generating vertical coordinates works in a similar way by looking at each word’s left and right bounds.
If you determine you must use "text" detection strategies, you should also consider using the "clip" parameter. This tells the table finder to only consider this rectangle’s area when looking for text and graphics. You may happen to know (or be able to determine by e.g. text searches) that your table must be located inside a certain bounding box.
Here is an example session. This is the “table” — even humans may have difficulties accepting it as such:

Our code snippet will find no table at first try.
But when switching to text strategies, we will get what we want:
tabs = page.find_tables() # locate tables
tabs.tables # found any?
[] # NO, the list is empty! Retry with changed strategies:
tabs = page.find_tables(horizontal_strategy="text", vertical_strategy="text")
tabs.tables
[<pymupdf.table.table object="" at="" 0x000001f184a1bed0="">] # we have a table now!
tab=tabs[0]
pprint(tab.extract()) # print its text content
[['Lorem', 'Ipsum', 'Has', 'Been'],
['', '', '', ''],
['The', 'Printing', 'And', 'Typesetting'],
['', '', '', ''],
['Industry’s', 'Standard', 'Text', 'Ever'],
['', '', '', ''],
['Since', 'The', '1500s.', '']]
</pymupdf.table.table>Please note that the algorithm automatically has determined that there must be empty text lines in between — because of the large inter-line distances.
Providing Explicit Coordinates
Another option is providing the x- or y-coordinates yourself. These are lists of float values that define the column or row borders of your table.
If provided, the algorithm will exclusively use this information and will not try to detect additional values. You therefore should make sure to also provide the left-most and right-most x-values (respectively top-most and bottom-most y-values).
Like the clip value, vertical_lines, respectively horizontal_lines may be a result of your own prior text searches, be entered by the user in a GUI application or be handed in externally by some upstream application.
Note on OCRed Tables
If a page has been OCRed, there will normally only exist text and no vector graphics. Most OCR engines do not scan line or rectangle drawings.
In these cases you will regularly have to use “text” strategies. PyMuPDF lets you determine whether the text has been created via OCR, enabling you to immediately choose the right detection strategy.
Unsuccessful Table Separation
The table finder usually has no problem separating multiple tables on the same if they each have proper grids.
In other cases, only a combination of “clip” and “strategy” parameters will lead to successful table extractions.
Here is an example that will resist any unsophisticated extraction approaches:
Only a combination of identifying the 4 clip rectangles and then executing 4 separate find_tables() methods (together with either “text” strategies or explicit x- and y-lines) will lead to acceptable results here.
Conclusion
In this blog we have seen that PyMuPDF’s table extraction feature provides the capability to deal with complex, non-rectangular tables.
There also are many ways to increase the table detection ratio by adjusting the algorithm’s strategy, thus limiting the need for manual/human intervention.
Like any other tool in this area (even if AI/ML technology-based), PyMuPDF’s table finder is no silver bullet. There will always be cases that are difficult or impossible to crack.
However, when PyMuPDF is embedded in a HITL application (Human In The Loop) that supports graphical interactions (like drawing lines or rectangles) results can be brought to perfection.
To learn more about PyMuPDF, be sure to check out the official documentation: https://pymupdf.readthedocs.io/en/latest/.
If you have any questions about PyMuPDF, you can reach the devs on the #pymupdf Discord channel.
Discuss This Article with the Community
Have a question, a different approach, or something you built after reading this? Share it on the forum or join the Discord, we'd love to hear from you.