Introducing the MuPDF.js API
Jamie Lemon·September 4, 2024

MuPDF.js is a JavaScript API provided by MuPDF, a lightweight, high-performance PDF, XPS, and eBook rendering engine developed by Artifex Software. MuPDF.js allows developers to integrate MuPDF's powerful document handling capabilities directly into web applications using JavaScript, enabling a wide range of PDF manipulation tasks such as viewing, rendering, and processing documents within a Node.js and/or browser environment.
Key Features of MuPDF.js
- Text Extraction: You can extract text content from PDF documents, which is useful for searching, indexing, and analyzing text data within PDFs.
- Document Manipulation: MuPDF.js provides functionality to merge, split, and manipulate PDF documents, which is particularly useful for applications that need to handle document workflows.
- Annotations: MuPDF.js supports reading and adding annotations to PDF documents, such as highlights, comments, and other markup tools.
- Redactions: MuPDF.js supports adding redactions to PDF documents making it suitable for sensitive business documents where certain data, such as personal information, financial details, or classified information, needs to be hidden from unauthorized viewers.
- Image and Graphics Rendering: Beyond simple text and page rendering, MuPDF.js supports high-quality rendering of images and vector graphics embedded in documents.
- PDF Rendering: MuPDF.js allows you to render PDF pages directly in a browser using HTML5 Canvas, making it easy to display PDF content in web applications without requiring any external plugins.
Next let’s explore some Basic and Advanced operations with code samples to guide our understanding. We will be assuming Node.js on a backend server for all our examples.
Basic Use Cases
Loading a document
Let’s test our MuPDF.js library out. Copy a PDF file over into the folder you are working from and ensure you can open it. Within the a node session try:
const mupdf = await import("mupdf")
let document = mupdf.Document.openDocument(fs.readFileSync("test.pdf"), "application/pdf")
console.log(document)You should receive a printout in the console with something like [PDFDocument #idNumber] - this means that the javascript runtime can see the PDF document object which mupdf.js has just loaded and returned.
Extracting text from a document
To extract text from the document instance we simply need to call the correct MuPDF.js API - toStructuredText - against the page we need. As text is extracted on a page by page basis, if we want to get all the text for all the pages of a document then we need to iterate the pages and extract the data as required.
For example:
let i = 0
while (i < document.countPages()) {
const page = document.loadPage(i)
const json = page.toStructuredText("preserve-whitespace").asJSON()
console.log(`json=${json}`)
i++
}
This will return structured objects with the bounding box, the font and other metadata along with the text value.
Rendering PDF pages to images
To convert a page to an image use the toPixmap method, after this the Pixmap data can be converted to the image format you require. The following script would get the first page of a document and convert it to image data.
const page = document.loadPage(0) // zero-indexed
let pixmap = page.toPixmap(mupdf.Matrix.scale(1,1), mupdf.ColorSpace.DeviceRGB, false, true)
let pngImage = pixmap.asPNG()
let base64Image = Buffer.from(pngImage, 'binary').toString('base64')The API allows for the resolution to be defined via a Matrix - you can increase the resolution by scaling the matrix parameter. You can also define if you want a transparent background or whether to also include any page annotations during the process - see our documentation for further explanation on the toPixmap method.
Advanced Use Cases
Combining PDFs
MuPDF.js is capable of combining or merging documents by copying document page content into a new document.
To merge a PDF with another PDF we need to use the GraftObject method and copy all the pages with all their content from the input documents into new pages within a new document. The new document is then saved out to the file system.
For example, we can create a file called “pdf-merge.mjs” as follows:
import * as fs from "fs"
import * as mupdf from "mupdf"
const scriptArgs = process.argv.slice(2)
function copyPage(dstDoc, srcDoc, pageNumber, dstFromSrc) {
var srcPage = srcDoc.findPage(pageNumber)
var dstPage = dstDoc.newDictionary()
dstPage.put("Type", dstDoc.newName("Page"))
if (srcPage.get("MediaBox"))
dstPage.put("MediaBox", dstFromSrc.graftObject(srcPage.get("MediaBox")))
if (srcPage.get("Rotate"))
dstPage.put("Rotate", dstFromSrc.graftObject(srcPage.get("Rotate")))
if (srcPage.get("Resources"))
dstPage.put("Resources", dstFromSrc.graftObject(srcPage.get("Resources")))
if (srcPage.get("Contents"))
dstPage.put("Contents", dstFromSrc.graftObject(srcPage.get("Contents")))
dstDoc.insertPage(-1, dstDoc.addObject(dstPage))
}
function copyAllPages(dstDoc, srcDoc) {
var dstFromSrc = dstDoc.newGraftMap()
for (var k = 0; k < srcDoc.countPages(); ++k)
copyPage(dstDoc, srcDoc, k, dstFromSrc)
}
function merge() {
var dstDoc = new mupdf.PDFDocument()
for (var i = 1; i < scriptArgs.length; ++i) {
console.log("OPEN", scriptArgs[i])
var srcBuf = fs.readFileSync(scriptArgs[i])
var srcDoc = new mupdf.PDFDocument(srcBuf)
copyAllPages(dstDoc, srcDoc)
}
console.log("SAVE", scriptArgs[0])
var dstBuf = dstDoc.saveToBuffer("compress")
fs.writeFileSync(scriptArgs[0], dstBuf.asUint8Array())
}
if (scriptArgs.length < 2)
console.error("usage: node pdf-merge.mjs output.pdf input1.pdf input2.pdf …")
else
merge()And then trigger this script with Node.js to merge two documents called “input1.pdf” and “input2.pdf” into a new file called “output.pdf” as follows:
node pdf-merge.mjs output.pdf input1.pdf input2.pdfThe resulting “output.pdf” will then represent these merged files.
Applying annotations to a PDF
There are many annotation types which are available with MuPDF.js and creating & adding them to a page involves creating them, setting their contents, their appearance and their metrics (bounding box rectangle). For example:
let annotation = page.createAnnotation("FreeText")
annotation.setContents("Hello World")
annotation.setDefaultAppearance("Helv", 16, [0,0,0])
annotation.setRect([0,0,100,100])Annotations also cover redaction types, which are suitable for dealing with classified information in documents.
Manipulating PDF pages
MuPDF.js is capable of cropping or rotating document pages.
To crop a page we need to set the “CropBox” property of the page box with the setPageBox method as follows:
page.setPageBox("CropBox", [ 0, 0, 500, 500 ])Here we must appreciate that MuPDF coordinate space is measured from the top left as follows:
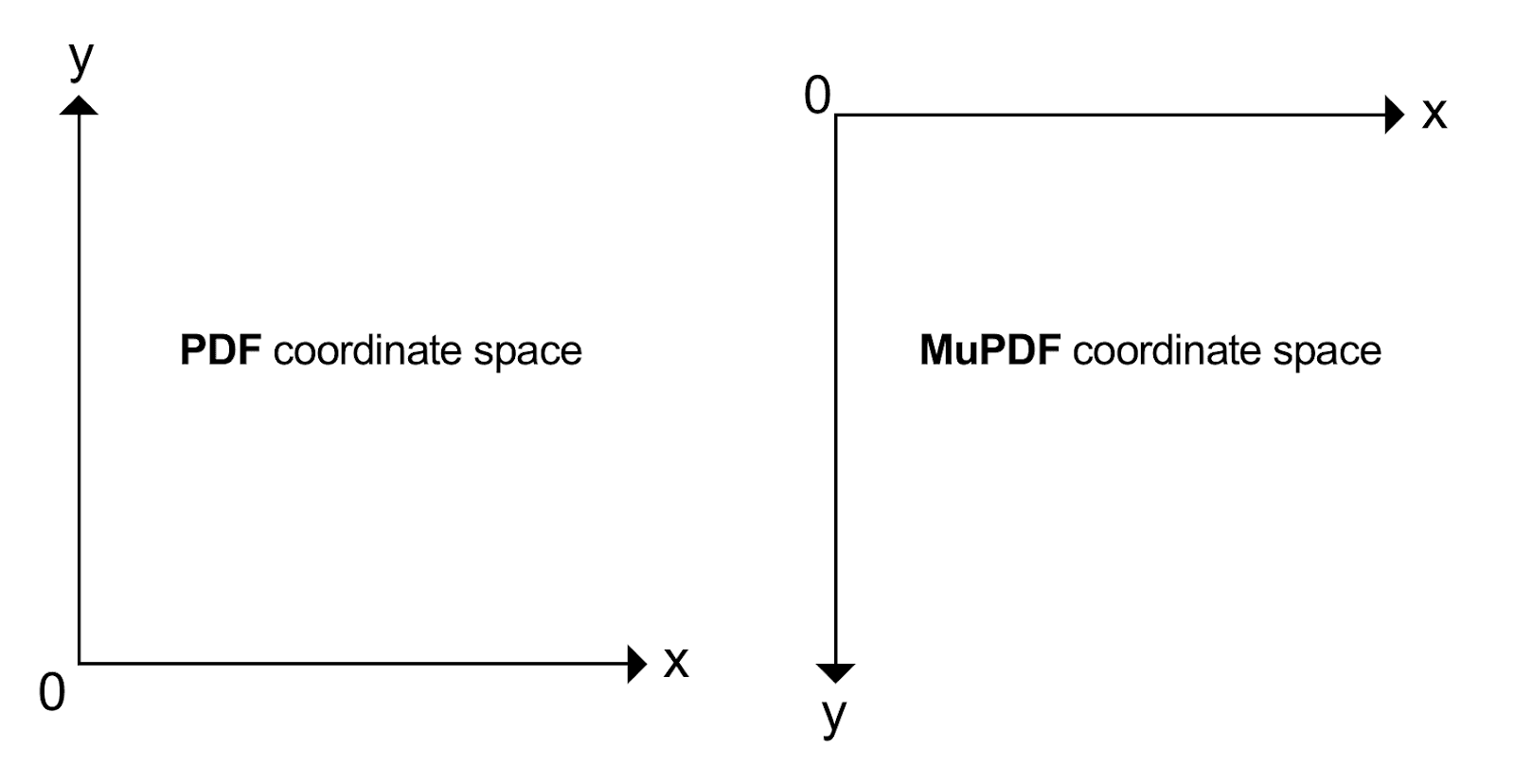
Please see The MuPDF Coordinate System for more.
Putting this together into handy script, let’s call it “pdf-crop.mjs”, might be as follows:
import * as fs from "fs"
import * as mupdf from "mupdf"
const scriptArgs = process.argv.slice(2)
function crop() {
let document = mupdf.Document.openDocument(fs.readFileSync(scriptArgs[1]), "application/pdf")
const page = document.loadPage(0)
const x1 = scriptArgs[2]
const y1 = scriptArgs[3]
const x2 = scriptArgs[4]
const y2 = scriptArgs[5]
page.setPageBox("CropBox", [ x1, y1, x2, y2 ])
fs.writeFileSync(scriptArgs[0], document.saveToBuffer("incremental").asUint8Array())
}
if (scriptArgs.length < 6)
console.error("usage: node pdf-crop.mjs output.pdf input.pdf 0 0 200 400")
else
crop()Conclusion
We’ve just outlined a few basic & advanced operations with MuPDF.js and shown how to understand the API from the code samples. Watch this space for an even more succinct wrapper API coming in the future to make working with MuPDF.js even easier and more reliable.
Resources
- MuPDF.js package on NPM
- “How to Guide with Node” MuPDF documentation
- Finally, please check MuPDF.js on Github - it includes many examples and is the place to add issues, share ideas, or ask questions directly on our Discord.