Extracting Text from Multi-Column Pages: A Practical PyMuPDF Guide
Harald Lieder·June 27, 2024

Introduction
This tutorial will teach you ways to extract text from multi-column pages using PyMuPDF. Pages where text appears in multiple columns are frequently encountered in newspapers or scientific articles.
We will start with ensuring that you have a Python programming environment containing all required components.
For the actual text extraction, we are providing the required Python sources and some example PDFs. When you execute the programs, they will create text files (in different formats) which represent the contents of all pages of the selected input file.
How the Programs Work
We are providing two programs which work in similar ways. Both loop through all pages of the input PDF using functions implemented in PyMuPDF or respectively PyMuPDF4LLM.
PyMuPDF4LLM, based on PyMuPDF, is a package that is specialized in text extraction especially useful in a LLM / RAG environment. In this package, recognizing multi-column text has been resolved in ways that can be used in more general situations.
Preparatory Work
Before we actually start coding, we need to make sure that all required Python components are installed.
Open a terminal window on your computer. Enter commands in that window as we proceed:
Make sure your Python version is high enough. Execute:
python -VOn some machines, like Linux or Mac OSX, you might have to write python3 instead of python. Please always assume python or python3 in all what follows – as is required on your machine.
The response is something like Python 3.12.3.
We need at least Python 3.9.0. If you have Python 3.8.x or less, then you must upgrade your Python first.
How this works is dependent on your Operating System, so please investigate the details in this unfortunate case.
Assuming from here on that your Python version indeed is compliant. The next thing to confirm is that your Python contains the standard installation program “pip”. This will be needed to install PyMuPDF and PyMuPDF4LLM.
Check if the following command in the terminal window works:
python3 -m pip –versionIf an error occurs saying that pip is not installed, you must install it before we can continue. This will never happen if you are working on a MS Windows machine. On Linux and Mac OSX machines execute the following:
Linux (Ubuntu example):
sudo apt update
sudo apt install python3-pipMac OSX:
python3 -m ensurepip --upgradeNow we are all set to do our required installations.
Enter the following commands in the terminal window. The first line will make sure that the Python installation program pip is on current level.
Line 2 will install PyMuPDF4LLM and, potentially also PyMuPDF if required.
python3 -m pip install --upgrade pip
python3 -m pip install pymupdf4llmDownloading and Executing the Programs
Please download the following files into some folder of your choice:
- markdowntext.py – program to extract multi-column text in Markdown format
- 2col2tables.pdf – example PDF having 2 columns and two tables.
- science-example1.pdf – example PDF from a scientific manual with 3 columns and an image
Open a terminal window there and execute the following commands (again, remember to potentially use python3 instead if required):
python markdowntext.py 2col2tables.pdf
python markdowntext.py science-example1.pdfFor each of the PDF documents, the script will create Markdown text files have the same name as the input file where the suffix .pdf has been replaced by suffix .md.
Inspecting the Code
The code could probably not be simpler!
9 import pymupdf4llm
10 import pathlib
11 import sys
12
13
14 filename = sys.argv[1] # read filename from command line
15 outname = filename.replace(".pdf", ".md")
16 md_text = pymupdf4llm.to_markdown(filename)
17
18 # output document markdown text as one string
19 pathlib.Path(outname).write_bytes(md_text.encode())
20 Please find comments by code line number below:
- Lines 9 to 11 import necessary Python packages.
- Line 14 reads the filename to process from the command line.
- Line 15 defines the name of the output text file. This will equal the document name where the file extension is replaced by the Markdown file extension.
- Line 16 produces the actual text.
- Line 19 writes the text to the defined output file. In order to support general UTF-8 encoded character sets, we convert the text to binary format and write that version to the file.
The above script can recognize multiple page text columns automatically – even if the column count does remain constant.
You can use the produced Markdown text file for many purposes like
- Feed it into an LLM / RAG process
- Render it with a Markdown renderer like GitHub, VS Code or react-markdown.
Inspecting the Results
Let us look at how the program reads the example pages.
In file 2col2tables.pdf, the page starts with two columns, followed by an area with one column, and finally going back to two columns again.
Red rectangles and arrows in the picture indicate the sequence by which text will be extracted.
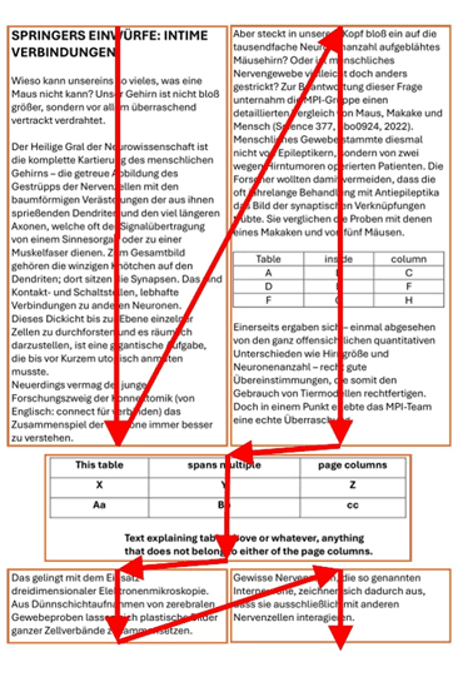
The algorithm detects 5 text blocks and realizes that there are two areas with two columns and one area with a single column.
From this it determines the overall sequence as indicated by the arrows.
Note
The two tables are detected and written in GitHub-compatible Markdown table format.
Here the second example, file science-example1.pdf:

This is a page from a scientific magazine which has text in three columns which are grouped around an image with some explanation. The image is spared from extraction.
Conclusion
Combining the power of PyMuPDF and PyMuPDF4LLM offers a wide range of innovative text extraction options beyond PyMuPDF alone.
Using an intuitive API, it can detect and extract text and tables on multi-column pages as it is customary in magazines and newspapers.
Related links:
- PyMuPDF.io – includes an installation-free PyMuPDF environment and an AI-supported answering machine about its features.
- PyMuPDF Documentation – the full documentation with all the details and many examples for beginners.
- MuPDF.NET – the .Net port of PyMuPDF for programming languages like C#, F#, VisualBasic.Net and more.
Discuss This Article with the Community
Have a question, a different approach, or something you built after reading this? Share it on the forum or join the Discord, we'd love to hear from you.