Building a Multimodal LLM Application with PyMuPDF4LLM
Benito Martin·September 30, 2024
Extracting text from PDFs is a crucial and often challenging step in many AI, and LLM (Large Language Model) applications. High-quality text extraction plays a key role in improving downstream processes, such as tokenization, embedding creation, or indexing in a vector database, enhancing the overall performance of the application. PyMuPDF is a popular library for this task due to its simplicity, high speed, and reliable text extraction quality.
In this blog, we will explore a recently launched free library by Artifex (the creators of PyMuPDF) called PyMuPDF4LLM. This new library is designed to simplify text extraction from PDFs and is specifically developed for LLM and Retrieval-Augmented Generation (RAG) applications. It offers two key formats:
pymupdf4llm.to_markdown(): Extracts content in Markdown format.pymupdf4llm.LlamaMarkdownReader(): Extracts content as a LlamaIndex document object.
We will focus on the to_markdown, as it includes several hyperparameters that enable features such as image extraction, making it suitable for both text and multimodal applications.
Let’s dive in!
Main Features
The full set of hyperparameters can be found in the API documentation. While we’ll cover a few of them in detail, the key features of PyMuPDF4LLM can be summarized as:
- Text extraction: Extracts content in Markdown format.
- Chunking: Supports adding metadata, tables, and image lists to the extracted content.
- Image extraction: Provides options to define image size, resolution, and format.
- Image embedding: Images are embedded directly within the Markdown output.
- Word extraction: Enables precise extraction of words from the PDF.
Text Extraction
This is the first step of the process. As shown below, the text is extracted into Markdown format, with the option to specify which pages of the document to extract.
!pip install -qq pymupdf4llmimport pymupdf4llm
md_text = pymupdf4llm.to_markdown(doc="/content/document.pdf",
pages = [0, 1, 2])Output text
#### Provided proper attribution is provided, Google hereby grants permission
to reproduce the tables and figures in this paper solely for use in
journalistic or scholarly works.\n\n## Attention Is All You Need\n\n\n**
Ashish Vaswani[∗]**\nGoogle Brain\n```\navaswani@google.com\n\n```\n**
Llion Jones[∗]**\nGoogle Research\n```\n llion@google.com\n\n```\n\n**
Noam Shazeer[∗]**\nGoogle Brain\n```\nnoam@google.com\n\n```\n\nChunking
This is where things get interesting. Plain Markdown text is not ideal for LLM applications — metadata plays a crucial role in enhancing the accuracy and performance of the model. As shown below, a vast amount of information can be extracted, including the document creation date, file path, image coordinates, and table of contents (TOC), all of which can enrich the application’s context.
md_text = pymupdf4llm.to_markdown(doc="/content/document.pdf",
pages = [0, 1, 2],
page_chunks = True)The output below is one of the multiple chunks that are extracted by adding the page_chunks option.
Output chunks
{'metadata': {'format': 'PDF 1.5',
'title': '',
'author': '',
'subject': '',
'keywords': '',
'creator': 'LaTeX with hyperref',
'producer': 'pdfTeX-1.40.25',
'creationDate': 'D:20240410211143Z',
'modDate': 'D:20240410211143Z',
'trapped': '',
'encryption': None,
'file_path': '/content/document.pdf',
'page_count': 15,
'page': 3},
'toc_items': [[2, 'Encoder and Decoder Stacks', 3], [2, 'Attention', 3]],
'tables': [],
'images': [{'number': 0,
'bbox': (196.5590057373047,
72.00198364257812,
415.43902587890625,
394.4179992675781),
'transform': (218.8800048828125,
0.0,
-0.0,
322.416015625,
196.5590057373047,
72.00198364257812),
'width': 1520,
'height': 2239,
'colorspace': 3,
'cs-name': 'DeviceRGB',
'xres': 96,
'yres': 96,
'bpc': 8,
'size': 264957}],
'graphics': [],
'text': '\n\nFigure 1: The Transformer - model architecture.\n\nThe Transformer follows this overall architecture using stacked self-attention and point-wise, fully\nconnected layers for both the encoder and decoder, shown in the left and right halves of Figure 1,\nrespectively.\n\n**3.1** **Encoder and Decoder Stacks**\n\n
**Encoder:** The encoder is composed of a stack of N = 6 identical'
'words': []}]
The table of contents (toc_items) is extracted in the format [lvl, title, pagenumber] where lvl is the hierarchy level (Heading would be 1, Subheading would be 2, 3… depending on the index level).
Image Extraction
In the previous example, no images were extracted, though we can see the related field images. To extract images, the write_images parameter must be set to True. Additionally, other parameters like, image format, dpi (resolution) or the file path to save the extracted images can be selected.
md_text = pymupdf4llm.to_markdown(doc="/content/document.pdf",
pages = [0, 1, 2],
page_chunks = True,
write_images = True,
image_path = "/content/images",
image_format = "jpg",
dpi = 200)By doing so, the images will be saved in the specified folder and a placeholder with the image path will be added into the respective field within the text markdown of the corresponding chunk. This place holder contains the document name, page number and image number.
Output images
'graphics': [],
'text': '\n\nFigure 1:
The Transformer - model architecture.\n\nThe Transformer follows
this overall architecture using stacked self-attention and point-wise,'In the case of the above output, the extracted image is shown below. The ability to extract images from the file enables their use in multimodal LLM applications, adding an extra layer of functionality and versatility.
Source: Arxiv
Additionally, you can embed images directly into the Markdown text as base64-encoded strings using the embed_images parameter. This approach integrates the images into the Markdown file, but it will increase the file size and does not allow for saving the images separately.
Table Extraction
Similarly to how images are identified, and their coordinates are included in the JSON dictionary, each recognized table will also have its coordinates added in the respective chunk
Output table
'toc_items': [[2, 'English Constituency Parsing', 9]],
'tables': [{'bbox': (108.0,
129.87200927734375,
508.73699951171875,
384.1730041503906),
'rows': 8,
'columns': 3}],
'images': [],
'graphics': [],
'text': 'Table 3: Variations on the Transformer architecture. Unlisted values are identical to those of the base\nmodel. All metrics are on the English-to-German translation development set, newstest2013. Listed\nperplexities are per-wordpiece, according to our byte-pair encoding, and should not be compared to\nper-word perplexitiesWord Extraction
Now that we have extracted text, tables, and images, we have additional metadata for our LLM application. To further enrich the metadata, we can use the extract_words parameter. This will include a list of words ordered in reading sequence associated with each specific chunk, complete with coordinates, just like the tables and images. This includes words inside table cells and multiple columns of a page similarly to the image below.

md_text = pymupdf4llm.to_markdown(doc="/content/document.pdf",
pages = [5, 6, 7],
page_chunks = True,
write_images = True,
image_path = "/content/images",
image_format = "jpg",
dpi = 200,
extract_words = True)Like in the previous outputs, we can see in the respective chunk fields the words’ sequence.
Output word sequence
'graphics': [],
'text': 'Table 1: Maximum path lengths,'
'words': [(107.69100189208984,
71.19241333007812,
129.12155151367188,
81.05488586425781,
'Table',
0,
0,
0),
(131.31829833984375,
71.19241333007812,
138.9141845703125,
81.05488586425781,
'1:',
0,
0,
1),
(144.78195190429688,
71.19241333007812,
185.4658203125,
81.05488586425781,
'Maximum',
0,
0,
2),
(187.65281677246094,
71.19241333007812,
204.46530151367188,
81.05488586425781,
'path',
0,
0,
3),Having this structure of our documents allows us to enrich our vector database with not only our Plain Markdown but also with images, tables, and words and its respective coordinates apart from being able to control some image parameters like resolution or format. This approach strongly enhances any application where information is required from PDFs and a high accuracy in the responses is required.
Notebook: Multimodal Application

Author: Benito Martin (AI Generated)
So, what can we do with PyMuPDF4LLM once we are able to extract our enriched text with metadata and images? LLM applications can perform a variety of tasks, but having the possibility to include text and images allows the use of a multimodal model to improve the performance of the application.
Let’s create a notebook to show how PyMuPDF4LLM can be used for a multimodal application using Llama Index as framework and Qdrant as Vector Store.
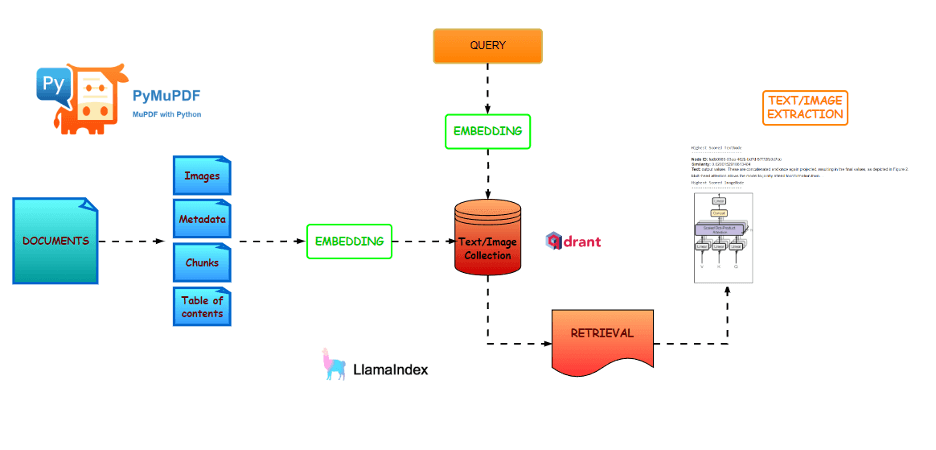
The application follows these steps. This is a simple workflow of a RAG (Retrieval Augmented Generation) architecture but with the addition of an image collection in the vector database (apart from the text collection) to be able to retrieve the images. Familiarity with this workflow and its common libraries is required:
- Libraries and dependencies installations: pymupdf4llm, llamaindex and openai clip embeddings for the images
- Document loading with pymupdf4llm
- Document object customization: selection of metadata based on the information extracted by pymupdf4llm
- Collections creation in vector store: text applications will have only one text collection but, in this case, we will add a second collection with image embeddings
- Indexing: this step is required to index our text and images inside the vector store
- Content retrieval: with a user query we will get out most similar text chunk and image
Step 1: Install Libraries and Define Environmental Variables
First, we need to install several libraries like pymupdf4llm, llama index, qdrant and clip embeddings to be able to generate embeddings for our images. Additionally, we need an OPENAI_KEY for the LLM model.
!pip install -qq pymupdf4llm
!pip install -qq llama-index
!pip install -qq llama-index-vector-stores-qdrant
!pip install -qq git+https://github.com/openai/CLIP.git
!pip install -qq llama-index-embeddings-clip
!pip install -qq llama-index qdrant-clientos.environ["OPENAI_API_KEY"] = userdata.get('OPENAI_API_KEY')
Step 2: Load Documents
Then we load our documents, generating chunks and extracting our images in jpg format for further processing. For simplification purposes we won’t select all options discussed above but this can be further customized depending on the application needs.
# Perform the markdown conversion
docs = pymupdf4llm.to_markdown(doc="/content/document.pdf",
page_chunks = True,
write_images = True,
image_path = "/content/images",
image_format = "jpg")Step 3: Customize Document Object
Llama Index requires a Document object. These Documents offer the possibility to include useful metadata and will create a dictionary on each chunk that will help on the retrieval step.
Therefore, we will customize it based on the extracted data from pymupdf4llm. The text will be the main content and as metadata we select toc_items, images, page, and file_path. This can be further extended and customized depending on the application, but having a rich content as we have seen, allows us to enhance the process from the first steps, which is key for an efficient LLM application.
llama_documents = []
for document in docs:
# Extract just the 'metadata' field and convert certain elements as needed
metadata = {
"file_path": document["metadata"].get("file_path"),
"page": str(document["metadata"].get("page")),
"images": str(document.get("images")),
"toc_items": str(document.get("toc_items")),
}
# Create a Document object with just the text and the cleaned metadata
llama_document = Document(
text=document["text"],
metadata=metadata,
text_template="Metadata: {metadata_str}\n-----\nContent: {content}",
)
llama_documents.append(llama_document)Step 4: Create Vector Store
Once our documents are in the required format and the images have been extracted, we can create two collections with Qdrant, one for the images and one for the text.
As mentioned before, these collections will store separately the text and images embedding but will retrieve both once a user makes a query.
# Initialize Qdrant client
client = qdrant_client.QdrantClient(location=":memory:")
# Create a collection for text data
client.create_collection(
collection_name="text_collection",
vectors_config=VectorParams(size=1536, distance=Distance.COSINE)
)
# Create a collection for image data
client.create_collection(
collection_name="image_collection",
vectors_config=VectorParams(size=512, distance=Distance.COSINE)
)
# Initialize Collections
text_store = QdrantVectorStore(
client=client, collection_name="text_collection"
)
image_store = QdrantVectorStore(
client=client, collection_name="image_collection"
)Step 5: Create a Multimodal Index
So now that our vector store is ready, we can store our images and text in the collections. For that, Llama Index provides the MultiModalVectorStoreIndex where we must define the path to the text and the images and TextNodes will be generated in the text collection and ImageNodes in the image collection.
storage_context = StorageContext.from_defaults(
vector_store=text_store, image_store=image_store
)
# context images
image_path = "/content/images"
image_documents = SimpleDirectoryReader(image_path).load_data()
index = MultiModalVectorStoreIndex.from_documents(
llama_documents + image_documents,
storage_context=storage_context)These nodes represent our chunks as we have previously predefined and in case, we want to make the chunks smaller LlamaIndex allows as well for this possibility. For simplification purposes, we will keep the size of the extracted chunks by pymupdf4llm.
Step 6: Retrieve Content
The last step is to ask a question and check the efficiency of our pipeline. With the following code we will retrieve 1 TextNodes and 1 ImageNode.
# Set query and retriever
query = "Could you provide an image of the Multi-Head Attention?"
retriever = index.as_retriever(similarity_top_k=1, image_similarity_top_k=1)
retrieval_results = retriever.retrieve(query)The following code snippet helps to visualize the highest scored node for image and text.
import matplotlib.pyplot as plt
from PIL import Image
def plot_images(image_paths):
images_shown = 0
plt.figure(figsize=(16, 9))
for img_path in image_paths:
if os.path.isfile(img_path):
image = Image.open(img_path)
plt.subplot(2, 3, images_shown + 1)
plt.imshow(image)
plt.xticks([])
plt.yticks([])
images_shown += 1
if images_shown >= 9:
break
retrieved_image = []
for res_node in retrieval_results:
if isinstance(res_node.node, ImageNode):
print("Highest Scored ImageNode")
print("-----------------------")
retrieved_image.append(res_node.node.metadata["file_path"])
else:
print("Highest Scored TextNode")
print("-----------------------")
display_source_node(res_node, source_length=200)We see that the result is satisfactory as we get in the text node the reference to the Figure 2, which is the same one that we get from the image node.

Conclusion
In this post, we built a simple RAG pipeline using the powerful features of pymupdf4llm to extract metadata and images from documents, improving the functionality of our application. With just a single line of code, all relevant data is extracted, significantly accelerating the pipeline creation process.
The unique capabilities of this new LLM tool from Artifex, combined with other integrations like LlamaMarkdownReader with LlamaIndex, open up new possibilities for improving LLM applications by reducing development time.
If you enjoyed reading this content, you can follow author Benito Martin on Github, star his repo, or share his content on LinkedIn.
Happy coding!
Discuss This Article with the Community
Have a question, a different approach, or something you built after reading this? Share it on the forum or join the Discord, we'd love to hear from you.