Artifex at EuroPython 2023
Jamie Lemon·July 27, 2023

This year’s EuroPython was in Prague with the main conference days being from Wednesday 19th - Friday 21st . I was there for the full 3 days as an attendee, but also to support our speaker, Harald Lieder, as he presented our Python talk on Thursday.
The event was really well organized with 142 talks to choose from over the 3 days. Talks were timed to perfection and the organizers ensured everything ran smoothly both during and between the sessions. Some of the main themes throughout were, as you may expect, AI, machine learning and large language models ( specifically how well these integrate with Python, and how well regarded Python is as a natural interface for these solutions ). Another key theme was “community” - an appreciation of the rich community which Python belongs to cannot be under-estimated.

Keynote from Ines Montani - Large Language Models: From Prototype to Production
Overriding Themes
- AI
- Machine Learning (ML)
- Natural Language Processing (NLP)
- Policies, ethics & Governance (i.e. how to ensure ethical AI with your business practice )
- Large Language Models (LLM)
- Open Source Software (OSS)
- Community
- Better Python with Python Enhancement Proposals (PEPs)
- Structured data from unstructured content (i.e. organizing & making sense of data)
- Future of computing processing power, managing performance against large operations
So, as I mentioned, I felt that the overall theme of AI was pretty pre-dominate throughout the conference as it featured in some form across most of the talks (also I lost count of the amount of times people mentioned ChatGPT 😉). Many solutions were centered around the automated processing of data through large models to get results. Ethics and responsible AI also featured heavily. For dedicated Python developers I think there was much focus on the Python ecosystem itself - for example other environments for Python, such as PyScript, were exciting to learn about.
The other main theme was Open Source software, but also “Community”. Indeed one keynote speaker was proposing that “Open Source” software is more like “community software”.
However, the theme of “structured data from unstructured content” resonated highly with me as this is something that we at Artifex are heavily concerned with on a day-to-day basis. How do we extract and organize data contained in PDFs? This is what we were there to discuss.
PDF Files, Information and Data
One thing to note about the PDF file format is that it tries to ensure identical appearance independent of hardware & software. As such PDF files contain embedded binary parts representing text, fonts, images, vector graphics and other content. Because PDF is intended really for human consumption (i.e. predominantly for people, not computers, to look at and understand) the data contained within isn’t required to be well structured for technological systems. Compare a PDF to a JSON dataset - there is no downstream application which a PDF really has to consider. However, in our JSON example, data needs to be well structured, semantically considered and consistent. This is because it will be used for a further endpoint - i.e. to populate databases or generate listed content for further consumption. However, as you can imagine, a PDF file is really an endpoint in itself, and that can be a problem when we need to obtain consistent data from our files. When information is required for another computer system, rather than a human being, then for PDF we need a good solution.
Structured Data out of Unstructured Content
Over the years many companies will have amassed much data in PDF documentation. But what if critical company data is contained here and now needs to be extracted and re-purposed for another context? In this case we need to pull structured data out of the unstructured files we have. The diagram below exemplifies what this could look like:
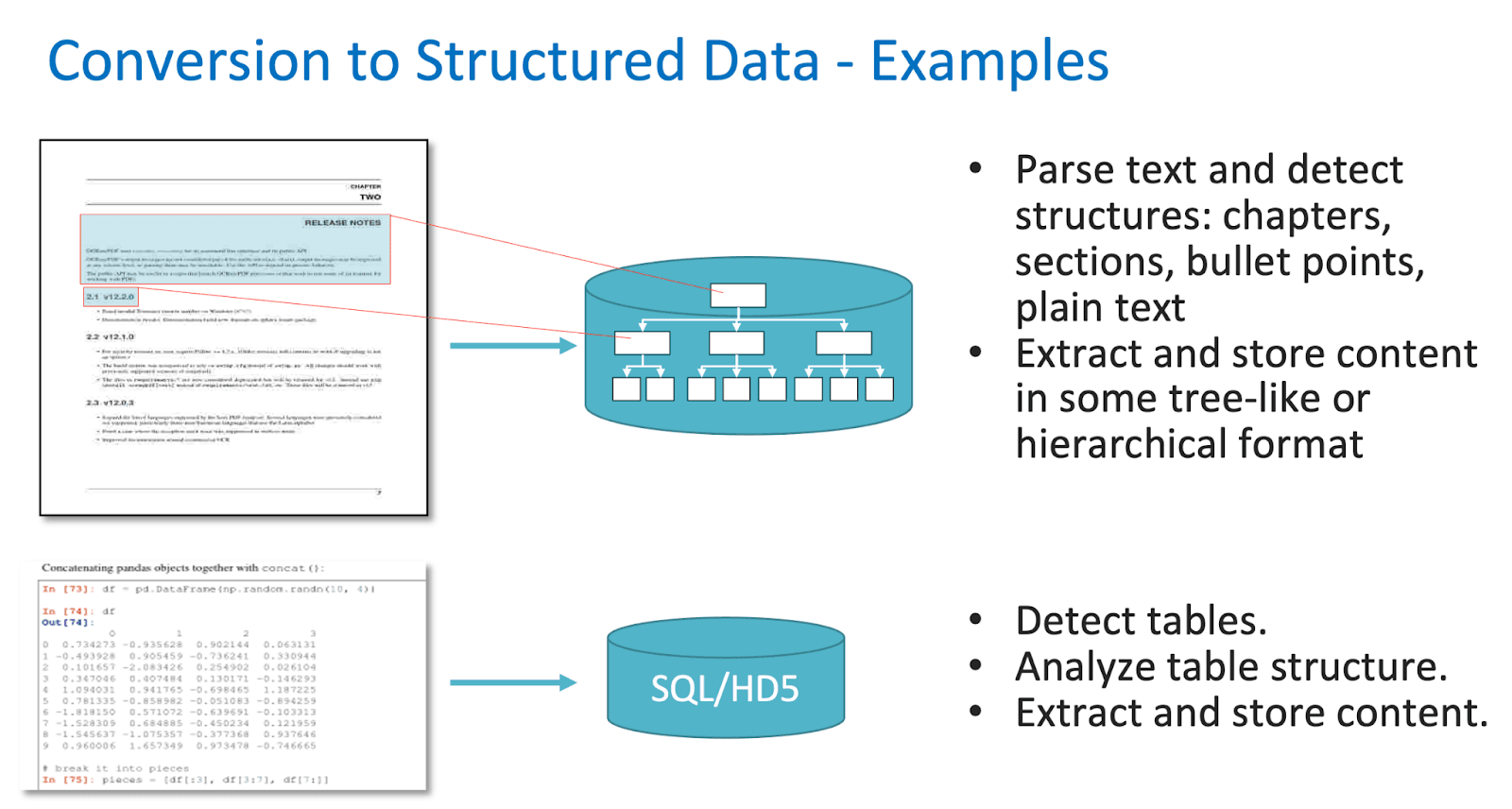
Imagine how this data within a PDF needs to be acquired in a new structure.
In this case you need software which can do this reliably and quickly - and for the Python ecosystem, this is where PyMuPDF comes in.
Our talk - High Volume Text Extraction with Open Source software

Our talk presented these problems along with a solution - our Open Source PyMuPDF. PyMuPDF is very capable when it comes to processing for high volume PDF operations due to its unparalleled speed and its full set of features.
Video
To understand the details, please view the full presentation here (skip to Timestamp: 2:32:35)
https://www.youtube.com/watch?v=vB-C7dBoxc8&t=9139s
Post-Talk Session
As this was quite a practical / pragmatic talk there were quite a few people asking for more hands on help. Harald took questions from a small group of people who wanted to know more. Always available to help when possible you can catch up with him on our Discord channel #pymupdf anytime!
Find out more on pymupdf.io which gives links to the Github repository, the documentation and more.
Discuss This Article with the Community
Have a question, a different approach, or something you built after reading this? Share it on the forum or join the Discord, we'd love to hear from you.