Explore Text Searching With PyMuPDF
Harald Lieder·October 16, 2023

PyMuPDF is a Python library that provides a wide range of features for working with document files. One of the most useful features of PyMuPDF is its ability to search for text in PDF and other documents.
This article is a more detailed continuation of Advanced Text Manipulation Using PyMuPDF.
“Text searching” means that you can specify a string (let’s call it “needle”) and use a method that finds one or more locations of it in the “haystack”, i.e. the page’s text.
Text “locations” are geometrical objects — rectangles or general quadrilaterals (tetragons) — inside each of which one occurrence of the needle can be found.
PyMuPDF offers more than just one approach to find what you need: let us walk through some of them in the following.
Simple Searches
Here’s an example code snippet that demonstrates how to use the search_for() method to find all occurrences of a given string in a PDF page:
import pymupdf # import PyMuPDF
from pprint import pprint # for easily printing results
# Open the PDF file
doc = pymupdf.open("example.pdf")
# load a desired page, pno is its 0-based page number
page = doc[pno]
# Search for the string "example"
needle = "example"
matches = page.search_for(needle)
# Print the match locations
if matches != []:
print(f"{page} shows '{needle}' in the following locations:")
pprint(matches)
else:
print("'{needle}' does not occur on {page}.")This code snippet opens a PDF file named example.pdf, loads some page and searches for the string “example”. It then prints the matches.
What are the differences if my document is not a PDF, but happens to be an XPS, EPUB, MOBI or other supported document type?
None at all: Every single code line above works in exactly the same way!
What if my needle contains spaces?
The returned locations wrap the complete needle text, respecting any spaces. This is also true when the needle is split across multiple lines in the document.
What if the needle is not horizontal, but “tilted” or rotated e.g. by 90 degrees?
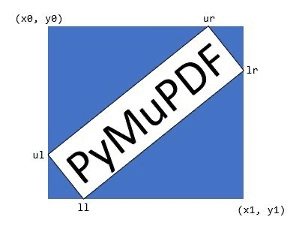
The standard format of the “matches” is the rectangle. A rectangle is given by the coordinates of its top-left (x0, y0) and bottom-right (x1, y1) points. In Document Management, rectangles will always have edges that are parallel to the coordinate axes.
If you know (or suspect) that your needles are not written horizontally, use the following format of the search method: page.search_for(needle, quads=True). In this case, a list of so-called quadrilaterals will be returned — no rectangles.
Each quad is defined by the coordinates of all four corners, which are called ul (upper-left), ur (upper-right), ll (lower-left) and lr (lower-right). The following picture illustrates this:
Can I tell the search method to only look at a certain area of the page?
Indeed: You can specify a “clip”, which will cause the search to only look inside this (rectangular) area. It can save a lot of code: if you for instance want only those needle occurrences that are located in the top-left quarter page (the page rectangle is defined as page.rect), you can specify clip = page.rect / 2. This computation divides all 4 rectangle coordinates by 2. Therefore, a Letter rectangle, Rect(0, 0, 612, 792), the top-left page quarter will become Rect(0, 0, 306, 396). And method page.search_for(needle, clip=clip) will deliver only those needle matches that are located in that area.
Advanced Searches
You may be interested in more criteria for locating text — not only the text itself. One may for instance need to tell apart paragraph headers from the text body for categorizing page content.
In such cases one is not interested in the text itself, but wants to only select by attributes like bold or italics, font name, font size, text color, line angle and so on.
PyMuPDF does allow you to do all that. However, combining all these options in the parameters of a hypothetical “search” method would yield a cumbersome, awkward API.
A much better approach is extracting the page’s complete text together with all its available meta-information and then use the Python language to down-select your required results.
Let’s look at another code snippet. It again searches for text containing our needle “example”, but only if it is written using the “Courier” font, has a font size no less than 10 points and is written horizontally.
import pymupdf # import PyMuPDF
from pprint import pprint # for easily printing results
# Open the PDF file
doc = pymupdf.open("example.pdf")
# load a desired page, pno is its 0-based page number
page = doc[pno]
# Search for the string "example"
needle = "example"
# prepare a list for all our matches
matches = []
# Extract the page’s complete text including meta-information,
# and skip text not containing our needle in a “Courier” font.
content = page.get_text("dict") # stacked dictionary object
for block in content["blocks"]: # blocks are the top hierarchy
for line in block["lines"]: # a block consists of lines
if line["dir"] != (1, 0): # not horizontal?
continue # skip the whole line
for span in line["spans"]: # span = text with identical properties
text = span["text"] # the text in the span
if needle not in text: # skip: needle is not part of it
continue
if ("Courier" not in span["font"] or
span[“size”] < 10): # wrong font or font size
continue
matches.append(pymupdf.Rect(span["bbox"])) # it’s a match!
# Print the match locations
if matches != []:
print(f"{page} shows '{needle}' mono-spaced here:")
pprint(matches)
else:
print("no mono-spaced '{needle}' found on {page}.")The above admittedly looks a little more complex than the first code snippet! But remember: we are talking about advanced text searches.
One detail above deserves some extra explanation: The “dir” key of the line dictionary contains the angle that the text of the line has relative to the x-axis. It is given as the (cosine, sine) values of that angle. Value (1, 0) uniquely defines the angle to be zero: cos(0) = 1, and sin(0) = 0. So text with this value is horizontal.
PyMuPDF’s “universal” extraction method page.get_text() offers a handful of variants, of which “dict” and “rawdict” are the most detailed ones. They represent a hierarchy of stacked dictionaries and provide access to the following information detail:
- Boundary boxes of blocks, lines, spans and (for “rawdict”) also characters
- Writing mode (horizontal, vertical like in some Asian scripts)
- Writing direction
- Font name, font size and other font details
- Super-script and hyphenation detection
- Text color
Like in page.search_for(), one of the most powerful parameters of page.get_text() is “clip”: It allows you to restrict text extraction to an arbitrary rectangular area and thus save coding effort.
Conclusion
PyMuPDF offers a number of ways to search for text and text properties on document pages, including PDF and other types.
A full range of text meta-information can also be extracted to either refine search criteria like text color, font size, writing angle and other properties, or passing these properties to downstream Artificial Intelligence/Machine Learning systems.
To learn more about PyMuPDF, be sure to check out the official documentation: https://pymupdf.readthedocs.io/en/latest/.
If you have any questions about PyMuPDF, you can reach the devs on the #pymupdf Discord channel.
Discuss This Article with the Community
Have a question, a different approach, or something you built after reading this? Share it on the forum or join the Discord, we'd love to hear from you.